Réseau de neurones artificiels : De quoi s’agit-il ?
Les réseaux de neurones artificiels ont révolutionné le domaine de l’intelligence artificielle et plus particulièrement, celui du machine learning. Inspirés par le fonctionnement et la structure du cerveau humain, ces systèmes informatiques sont conçus pour résoudre des problèmes complexes, effectuer des tâches cognitives et prendre des décisions en toute autonomie.
Qu’est-ce qu’un réseau de neurones artificiels ? Comment fonctionne-t-il ? Quels sont les différents types de réseaux neuronaux profonds ? Et enfin, qu’est-ce que les réseaux de neurones liquides ? Zoom sur les réseaux neuronaux artificiels, cette avancée majeure de l’IA.
Sommaire
Réseau de neurones artificiels : définition

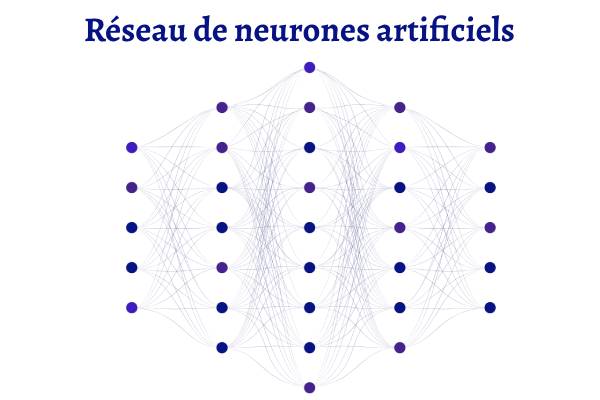
Aussi appelés « réseaux de neurones simulés », les réseaux de neurones artificiels (Artificial Neural Network) sont à la base du deep learning (apprentissage profond). Inspiré du fonctionnement du cerveau humain, il est lui-même un sous-ensemble du machine learning (ou apprentissage automatique). Les réseaux de neurones artificiels imitent la structure et le fonctionnement du cerveau humain. Ils se composent de plusieurs couches de nœuds de calcul. Ces nœuds représentent les neurones. La première couche correspond à la couche d’entrée. La dernière, appelée couche de sortie, transmet les résultats. Entre les deux se trouvent une ou plusieurs couches de nœuds intermédiaires chargées de traiter l’information. Plus les couches sont nombreuses, plus les tâches que le modèle est en mesure d’effectuer sont complexes. Pour apprendre et améliorer leurs performances, les réseaux de neurones sont alimentés par des données d’entraînement.
Les algorithmes d’apprentissage font donc appel à la data science. Ils sont employés pour trier et catégoriser rapidement des données. Les outils de deep learning sont fréquemment utilisés en sciences informatiques. Ils sont en mesure d’exécuter des tâches répétitives beaucoup plus rapidement que les êtres humains. C’est pourquoi leurs applications sont très variées : marketing, cybersécurité, assistants vocaux, analyse d’images, reconnaissance vocale et faciale, etc. Par exemple, l’algorithme de recherche Google est un réseau neuronal.
Réseaux de neurones artificiels : composition et fonctionnement

1) Structure de réseau neuronal simple
Les réseaux de neurones artificiels simples sont constitués de trois couches interconnectées :
- Une couche d’entrée : c’est par cette couche que les informations externes entrent dans le réseau de neurones. Les nœuds d’entrée analysent et trient les données, puis les transfèrent aux couches suivantes.
- Une ou plusieurs couches cachées intermédiaires : un réseau neuronal peut comporter de nombreuses couches intermédiaires. Les données sont transmises à ces couches nodales par la couche d’entrée ou par d’autres couches cachées. Chaque couche intermédiaire traite la sortie de la couche qui précède et transfère les données à la suivante.
- La couche de sortie : il s’agit de la dernière couche. C’est elle qui communique le résultat des traitements de données successifs réalisés par le réseau de neurones artificiels. La couche de sortie peut comporter des nœuds multiples ou uniques. Ainsi, si le problème à résoudre est de l’ordre d’une classification binaire, la couche de sortie sera composée d’un nœud de sortie qui transmettra le résultat dans un langage binaire (1 ou 0). S’il s’agit d’un problème de classification multiclasses, la couche de sortie peut comporter plusieurs nœuds de sortie.
2) Structure de réseau neuronal profond
Un réseau de neurones profonds est, quant à lui, composé de plusieurs couches cachées pouvant comporter des millions de neurones interconnectés. On parle de « poids » pour désigner la valeur des connexions entre les nœuds. Si le nœud stimule un autre nœud, le poids correspond à un nombre positif. Si, au contraire, les nœuds ne correspondent pas, le poids est alors un nombre négatif. Plus la valeur de poids est élevée, plus l’impact sur les autres nœuds est important.
En principe, un réseau de neurones artificiels peut connecter tous les types d’entrées et de sorties. Cela implique néanmoins de pratiquer un entraînement beaucoup plus poussé que pour les autres modèles de machine learning. En effet, alors qu’une structure de réseau neuronal simple a besoin de centaines ou de milliers de données d’entraînement, une architecture de réseaux de neurones profond en nécessite des millions.
Les 3 types de réseaux neuronaux artificiels
1- Réseaux neuronaux convolutifs
Dans une structure de réseaux de neurones convolutifs, les couches cachées effectuent des convolutions. C’est-à-dire des fonctions mathématiques précises telles que le filtrage ou la synthèse. Ce type de réseau de neurones artificiels sert notamment à la classification et à la reconnaissance des images. Le modèle est capable de traiter les nouvelles images malgré d’éventuelles complications tout en conservant les caractéristiques nécessaires à une prédiction pertinente. Pour ce faire, chacune des couches intermédiaires traite et extrait différents éléments de l’image comme la couleur, la lumière, la profondeur, etc.
2- Réseaux neuronaux à action directe
Les réseaux de neurones à action directe (Feedforward Neural Network) effectuent un traitement des neurones à sens unique : du nœud d’entrée au nœud de sortie. Chaque nœud que comporte une couche est relié à chaque nœud de la suivante. Un réseau neuronal à action directe fonctionne de façon rétroactive pour affiner ses prédictions au fur et à mesure.
3- Algorithme de rétropropagation
Les réseaux de neurones artificiels apprennent continuellement en exécutant des boucles de rétroaction corrective afin d’optimiser leurs prédictions. Autrement dit, les données se déplacent du nœud d’entrée au nœud de sortie en empruntant différents trajets au sein du réseau neuronal. Or, seulement le chemin qui fait correspondre le nœud d’entrée au bon nœud de sortie est correct. Pour trouver le bon trajet, le réseau de neurones artificiels effectue une boucle de rétroaction qui suit un processus précis. Pour commencer, chacun des nœuds émet une hypothèse sur le nœud suivant.
Il vérifie ensuite si sa supposition est exacte. Plus un trajet mène à un nombre important de suppositions exactes, plus le nœud lui attribue des valeurs de poids élevées. Au contraire, des valeurs de poids plus faibles sont attribuées aux chemins qui aboutissent à des suppositions erronées. Le nœud émet une nouvelle hypothèse pour le prochain point de donnée en empruntant les trajets aux valeurs de poids plus élevées. Puis, il reproduit la première étape et ainsi de suite.
Réseau de neurones liquides : quelle est cette découverte étonnante du MIT ?

1) Définition
Les réseaux de neurones liquides (LNN) ont été développés par une équipe de chercheurs du CSAIL du MIT dirigée par Daniel Rus. L’objectif des chercheurs était de mettre au point des réseaux de neurones artificiels efficaces et précis qui pouvaient être exécutés sur les ordinateurs sans que cela nécessite de se connecter au cloud. Pour ce faire, les chercheurs se sont inspirés des systèmes de machine learning. Ils se sont également intéressés à la recherche biologique sur le fonctionnement neuronal de petits organismes. Le ver C. Elegans, notamment, est en mesure de réaliser des tâches complexes alors qu’il ne possède que 302 neurones.
Les recherches de Rus et son équipe ont débouché sur la création de réseaux de neurones liquides. Ces derniers diffèrent des systèmes classiques de deep learning. Leur formule mathématique nécessite une puissance de calcul moins élevée et permet une stabilité des neurones durant l’entraînement. Les réseaux de neurones liquides reposent sur l’application d’équations différentielles ajustables dynamiquement. Contrairement aux réseaux neuronaux classiques, ils sont ainsi en mesure de s’adapter à des situations inédites après avoir été entraînés.
Rus explique que son équipe augmente « la capacité d’apprentissage de représentation d’un neurone de deux insights par rapport aux modèles existants ». Le premier insight est en quelque sorte un « modèle d’espace d’états » qui améliore la stabilité des neurones lors de l’apprentissage. Ensuite, des non-linéarités sont soumises aux entrées synaptiques dans le but d’accroître l’expressivité du modèle durant l’apprentissage et l’inférence (la formulation de prédictions).
La structure des connexions d’un réseau de neurones liquides diffère également de celle des réseaux neuronaux traditionnels. L’architecture des LNN permet à des connexions de se créer latéralement et de manière récurrente dans une même couche. Les réseaux de neurones liquides peuvent ainsi apprendre continuellement et adapter dynamiquement leur comportement. L’intérêt de ce modèle réside dans le fait qu’il peut continuer à s’adapter de façon dynamique après sa formation en s’appuyant sur les jeux de données qui lui sont transmis. Il offre donc plus de flexibilité et d’adaptabilité.
2) Avantages
L’un des principaux atouts du réseau de neurones liquides est leur caractère compact. Ainsi, un réseau de neurones artificiels traditionnel est en moyenne constitué de 100 000 neurones artificiels. Environ 500 000 paramètres sont nécessaires pour exécuter une tâche comme maintenir une voiture sur la bonne voie. L’équipe de Daniel Rus est parvenue à entraîner un réseau de neurones liquides de seulement 19 neurones à exécuter cette même tâche.
Cette diminution importante comporte plusieurs avantages. Elle permet avant tout au modèle d’être opérationnel sur des ordinateurs peu puissants, des appareils edge et des robots. En outre, une plus petite quantité de neurones rend le modèle beaucoup plus simple à interpréter. Or, l’un des grands enjeux de l’IA est la lisibilité des réseaux. En effet, jusqu’alors, comprendre la manière dont un réseau de neurones artificiels aboutissait à un résultat spécifique s’avérait très complexe.
Par ailleurs, les LNN interprètent plus facilement les relations causales qu’ils peuvent alors étendre à des situations nouvelles. Les modèles de deep learning habituels ont du mal à établir des causalités. Ils apprennent à partir de patterns sans lien avec les problèmes pour lesquels ils ont été conçus. Les chercheurs du MIT ont entraîné des réseaux de neurones liquides et d’autres modèles de deep learning à repérer des objets à partir d’une série de vidéos réalisée dans les bois durant l’été. Quand ils ont testé le LNN sur une situation inédite comme un paysage d’hiver, le système était toujours capable d’exécuter la tâche de manière précise. Les performances du réseau de neurones profonds classiques étaient au contraire altérées.
Au lieu de se focaliser sur le contexte, le réseau de neurones liquides se concentre sur la tâche. Les systèmes neuronaux classiques, quant à eux, dirigent essentiellement leur attention sur le contexte et non sur la tâche. Un réseau de neurones liquides accorde plus d’importance aux caractéristiques principales de la tâche. Pour exécuter une tâche de détection d’objet par exemple, le LNN va principalement se focaliser sur les objets. Le réseau de neurones liquides est par conséquent en mesure de s’adapter lorsque le contexte est modifié. Les autres systèmes de deep learning, quant à eux, focalisent leur attention sur des éléments non essentiels. Les LNN ont donc une meilleure capacité d’adaptation.
3) Applications
Le réseau de neurones liquides constitue une avancée majeure dans le secteur de la robotique et dans le domaine des véhicules autonomes. Les LNN sont principalement utilisés pour le traitement de flux de données en continu, tels que les séquences de mesures de température, la vidéo en streaming, etc. Pour bien fonctionner, le système doit traiter des données de série temporelle. Ce modèle n’est pas applicable à des jeux de données statiques de type ImageNet.
Les réseaux de neurones liquides s’adaptent très bien aux programmes gourmands en puissance de calcul ou avec des exigences de sécurité importantes. C’est notamment le cas des véhicules autonomes et de la robotique dont les modèles de machine learning sont constamment alimentés par des données. L’équipe de chercheurs du CSAIL a testé avec succès les réseaux de neurones liquides sur des systèmes dotés d’un seul robot. Leur objectif est d’élargir leurs tests à des configurations multirobot et à d’autres genres de données afin d’explorer tout le potentiel et les limites des réseaux de neurones liquides.
FAQ – Réseau de neurones artificiels
En compléments !













✔ Reporting puissants
✔ Assistance 24/7

✔ 300+ intégrations
✔ Assistance 24/7
Le Consultant Digital, cest votre consultant full-online !
Lisez le blog, accédez à des ressources gratuites et posez vos questions à nos consultants.






{kind=link}