Big Data : définition et enjeux à l’ère du numérique
À l’ère du numérique, le concept de « Big Data » est de plus en plus présent. Mais que se cache-t-il réellement derrière cette notion souvent floue ? Le Big Data se présente comme un concept clé dans le paysage technologique actuel. Il se caractérise par des quantités massives de données complexes et variées. Ce volume d’informations dépasse les capacités de traitement traditionnelles, exigeant des méthodologies et des outils innovants pour extraire des insights exploitables.
Dans cet article, nous nous sommes intéressés aux mégadonnées et à leurs applications. Définition du Big Data, origines, utilités et impact sur les différents secteurs, découvrez ce qu’il faut savoir sur cette notion essentielle à l’heure du digital.
Sommaire
Big Data : définition et origine

Qu’est-ce que le Big Data ?
« Big Data » est la contraction de « Big volume of data », qui se traduit littéralement en français par « gros volume de données ». Mais le terme de « Big Data » n’a pas seulement un sens quantitatif. Il sert également à désigner les techniques, outils, stratégies et technologies destinés à gérer de grandes quantités de données. En effet, de tels volumes d’informations ne peuvent pas être traités de la même manière que des bases de données classiques. Les outils et les process habituels ne suffisent pas. Il devient alors indispensable de se tourner vers des dispositifs spécifiques.
Plus globalement, le Big Data correspond à l’art de traiter de grands ensembles de données. Alors que les entreprises disposent aujourd’hui d’énormes bases de données, elles ne savent pas toujours comment gérer et exploiter ces informations. Le plus souvent, elles n’en traitent qu’une infime partie. Le Big Data leur permet d’exploiter ces données et d’en tirer le meilleur parti. Elles disposent ainsi d’informations importantes pour optimiser leurs stratégies.
Quelles sont les origines du Big Data ?
La notion de Big Data est récente. Si l’on se réfère à Google Trend, on s’aperçoit qu’elle suscite réellement l’intérêt depuis 2012. Néanmoins, de grandes bases de données se développent à partir des années 1960. On voit apparaître à cette époque les premiers centres de données et les bases de données relationnelles. Ce n’est qu’en 2005 que l’on se rend compte des quantités astronomiques de données engendrées par l’utilisation des plateformes en ligne telles que Facebook et YouTube. Le framework Hadoop voit alors le jour. Cette infrastructure logicielle Java open source est conçue pour stocker et traiter de grandes bases de données. En parallèle, les développeurs utilisent de plus en plus à cette époque les bases de données NoSQL qui servent à stocker des données non structurées.
Depuis les années 2000, les quantités de données en ligne ont considérablement augmenté. Les internautes continuent de générer de très gros volumes de données. Par ailleurs, l’Internet of Things (IoT), c’est-à-dire le réseau de terminaux et d’objets connectés à Internet (connexions wifi, bracelets connectés, applications mobiles, etc.) s’est considérablement étendu. Toujours plus d’informations sont récoltées sur les habitudes des utilisateurs et les produits. En outre, l’avènement de l’intelligence Artificielle et, en particulier, du machine learning, génère toujours plus de données.
L’apparition de frameworks comme Hadoop a permis au Big Data de se développer. Ces infrastructures simplifient en effet le traitement des bases de données et permettent de diminuer les coûts liés au stockage. Le Big Data a énormément évolué durant ces vingt dernières années. Pourtant, les entreprises et les organisations commencent tout juste à percevoir son utilité. Le cloud computing a ouvert de nombreuses possibilités en facilitant le traitement des données par les développeurs. De plus, l’utilisation des bases de données graphiques s’est accrue, simplifiant l’analyse et l’exploitation des informations.
Big Data : définition par les 3 « V »
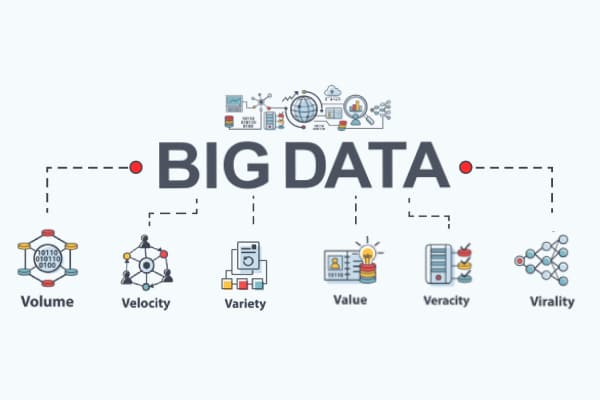
Les 3 « V » selon Doug Laney
Doug Laney, un analyste de l’entreprise américaine Gartner, a donné en 2001 une définition simple du Big Data. Cette explication, basée sur la théorie des 3 V, permet de mieux comprendre le concept. D’après Laney, il est possible de le définir à travers trois notions qui commencent toutes par la lettre « V » :
- Volume : le Big Data se définit avant tout par la quantité de données à traiter. Il se caractérise par des ensembles de données nettement plus grands que les bases de données classiques, ce qui fait naître des enjeux techniques et technologiques. Stocker et traiter de tels volumes de données nécessite en effet l’utilisation d’outils, d’infrastructures et de techniques adaptées comme le Cloud computing, la mise en réseau, etc.
- Vélocité : la volumétrie n’est pas le seul facteur qui caractérise le Big Data. La vitesse de circulation des données est aussi à prendre en compte. Les informations proviennent de sources diverses et sont souvent traitées en temps réel afin de créer des insights et de mettre à jour les bases de données. La technique de batching, qui consiste à automatiser des suites de commandes effectuées en série, était jusqu’à présent le procédé de référence. Il est peu à peu remplacé par le streaming de données simultané ou quasi simultané. En matière de Big Data, il est parfois nécessaire de traiter des données en temps réel ou quasi réel.
- Variété : de grandes quantités de données impliquent en outre une grande diversité d’informations. Dans le cadre de bases de données relationnelles, les data warehouses structurent et classent les informations. Dans les data lake, autrement dit les outils destinés à gérer les grands ensembles de données, les données ne sont pas structurées (ou seulement semi-structurées).
En somme, d’après la définition de Laney, le Big Data consiste à gérer de grandes quantités de données variées, complexes et, le plus souvent, non structurées. Elles doivent circuler rapidement au sein d’un système donné. Les outils traditionnels de gestion de données ne sont pas capables de traiter de tels volumes. C’est pourquoi la notion de Big Data se réfère également aux méthodes et technologies destinées à gérer et stocker ces systèmes.
Les autres « V »
Au fil du temps, des « V » supplémentaires sont venus s’ajouter à la définition de Laney afin de mettre l’accent sur les autres enjeux générés par le Big Data :
- Véracité : le problème de la Data Quality est un défi majeur dans le Big Data. La complexité des données et la diversité des sources peuvent rendre la qualité des données difficiles à évaluer et, in fine, nuire à la pertinence des analyses.
- Variabilité : les données évoluent dans le temps et perdent en qualité et en pertinence. Il est donc primordial de disposer d’outils capables de repérer et de trier les données de moins bonne qualité pour une analyse fiable et qualitative.
- Valeur : l’objectif principal du Big Data est de créer de la valeur. Cependant, il est souvent difficile de générer de la valeur à partir de grands volumes de données du fait de la complexité des process et des systèmes.
À voir aussi : Comment digitaliser votre entreprise ?
À quoi sert le Big Data ?

Le Big Data est employé par les entreprises dans tous les secteurs d’activité afin de les aider à atteindre différents objectifs, tels que :
- améliorer leur service client ;
- augmenter leur chiffre d’affaires ;
- optimiser leurs campagnes marketing grâce à une connaissance approfondie des habitudes et des besoins de leur clientèle cible ;
- etc.
Le Big Data aide les entreprises à rester compétitives face à des concurrents qui n’exploitent pas pleinement les données. Elles peuvent se baser sur les informations pour prendre rapidement des décisions pertinentes. Une entreprise est dite « data driven » (« dirigée par les données ») lorsqu’elle s’appuie entièrement sur les données pour se développer.
Une entreprise peut notamment se servir du Big Data pour mieux connaître les attentes et les besoins de leur cible. Elle peut exploiter ces données pour améliorer ses produits et personnaliser ses campagnes marketing afin d’améliorer la fidélisation de ses clients et d’augmenter ses ventes. Le Big Data est également régulièrement employé dans la recherche médicale. Il peut alors servir à :
- améliorer la précision et la fiabilité des diagnostics ;
- repérer les facteurs de risques de certaines pathologies ;
- prévoir et suivre des épidémies ;
- etc.
De manière générale, tous les secteurs ont recours au Big Data. Dans le secteur du transport, l’utilisation de données permet d’optimiser le suivi des itinéraires de livraison et des chaînes de logistique. Le Big Data est aussi utilisé dans le secteur de l’énergie dans le but de contrôler les réseaux électriques ou de suivre les opérations. Il permet aussi de mettre à jour de potentielles zones de forage. Dans le domaine de la finance, il sert à analyser en temps réel les évolutions du marché et anticiper les risques. Enfin, le Big Data est exploité par les pouvoirs politiques. Les gouvernements y ont recours pour des projets de ville intelligente (Smart City) ou pour la prévention de la délinquance par exemple.
À lire aussi : Fichier Client
FAQ – Big Data définition
En compléments !













✔ Reporting puissants
✔ Assistance 24/7

✔ 300+ intégrations
✔ Assistance 24/7
Le Consultant Digital, cest votre consultant full-online !
Lisez le blog, accédez à des ressources gratuites et posez vos questions à nos consultants.






{kind=link}